Планирование пути
Чтобы можно было следить за работой планировщиков, написаны демо-приложения
в пакете project.find_path.find_path_core.demo. Они
используются класс GLScene.
Почти все нужные методы уже прописаны в нём.
Для его использования необходимо написать класс-потомок, у которого должны быть определены следующие методы:
- инициализация
init() - рисование
render() - изменение состояния сцены
changeState()
По пробелу запускается обработка сцены и приостанавливается. Простейший пример
использования GLScene лежит по адресу: project/core/gl_scene/src/demo_gl_scene.cpp
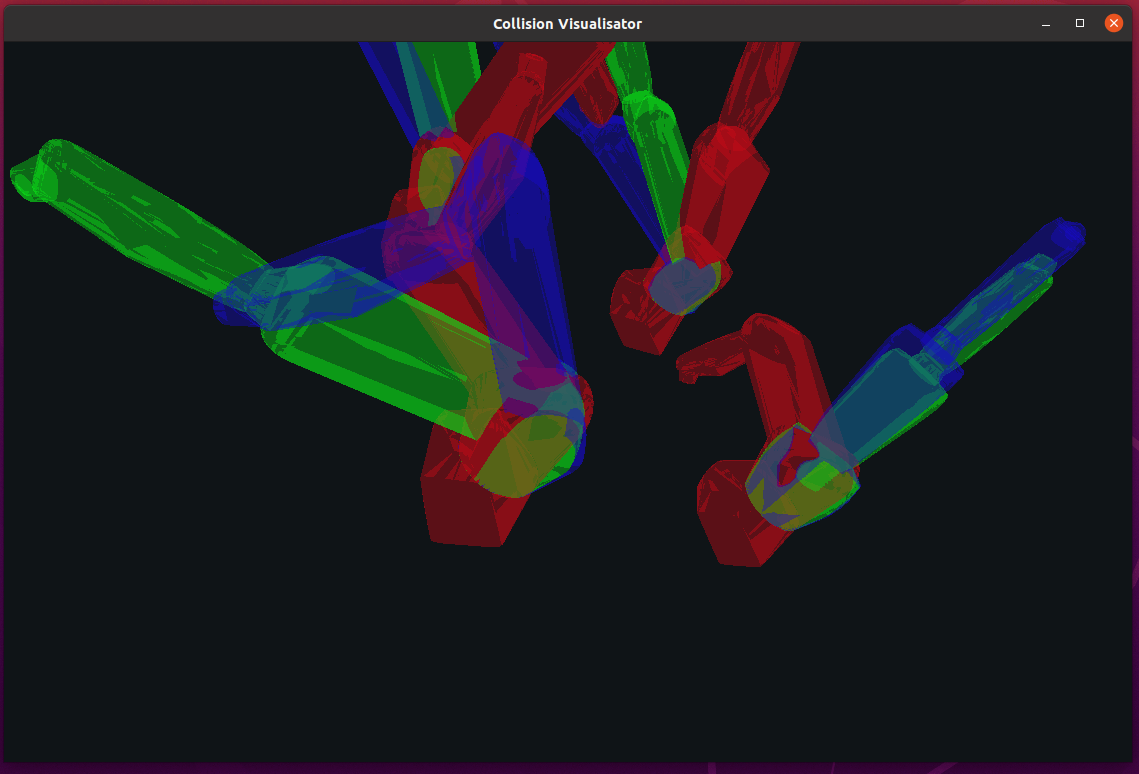
Красным рисуется начальная конфигурация робота, зелёным - конечная. Синим обозначается текущая перебираемая конфигурация.
Базовый планировщик
Все планировщики пути должны наследовать базовый класс
project.core.find_path.find_path_core.base.PathFinder.
Он является основным связующим звеном между коллайдерами и сценами.
Конструктор базового планировщика:
/**
* конструктор
* @param scene сцена
* @param showTrace флаг, нужно ли выводить информацию во время поиска пути
* @param threadCnt количество потоков планировщика
*/
PathFinder(const std::shared_ptr<bmpf::Scene> &scene, bool showTrace, int threadCnt = 1);
Хотя на данный момент многопоточные режимы не используются, тем не менее планировщик сразу проектировался как многопоточный. Поэтому в зависимости от количества потоков, он инициализирует в конструкторе коллайдер либо однопоточным, либо синхронным:
if (threadCnt != 1)
_collider = std::make_shared<SolidSyncCollider>(threadCnt);
else
_collider = std::make_shared<SolidCollider>();
Планирование нужно выполнять пошагово для рисования, а обычные задачи требуют сразу сформировать путь:
/**
* Поиск пути
* @param startState стартовое состояние
* @param endState конечное состояние
* @param errorCode в эту переменную записывается код ошибки
* @return построенный путь
*/
std::vector<std::vector<double>>
PathFinder::findPath(const std::vector<double> &startState, const std::vector<double> &endState, int &errorCode) {
_startState = startState;
_endState = endState;
_startTime = std::chrono::high_resolution_clock::now();
prepare(startState, endState);
if (_errorCode != NO_ERROR) {
errorCode = _errorCode;
return {};
}
std::vector<double> actualState;
// если очередной такт поиска пути не последний
while (!findTick(actualState)) {};
if (_errorCode != NO_ERROR)
return {};
// строим путь
buildPath();
auto endTime = std::chrono::high_resolution_clock::now();
_calculationTimeInSeconds =
(double) std::chrono::duration_cast<std::chrono::milliseconds>(endTime - _startTime).count() / 1000;
errorCode = _errorCode;
return _buildedPath;
}
Сначала выполняется подготовка планировщика
/**
* подготовка к планированию
* @param startState начальное состояние
* @param endState конечное состояние
*/
virtual void prepare(const std::vector<double> &startState, const std::vector<double> &endState) = 0;
Потом в бесконечном цикле запускается такт планирования, пока оно не будет окончено:
/**
* такт поиска
* @param state текущее состояние планировщика
* @return возвращает true, если планирование закончено
*/
virtual bool findTick(std::vector<double> &state) = 0;
Когда планирование закончено, вызывается построение пути
/**
* построить путь, построенный путь должен быть сохранён в переменную _buildedPath
*/
virtual void buildPath() = 0;
Все три последних метода должны быть реализованы в потомке, т.к. являются чисто виртуальными.
Сетка планирования
Суть планирования на сетке заключается в том, что каждой вещественной
координате состояния мы ставим в соответствие целочисленную
координату из заданного диапазона.
Данная логика реализована в классе
project.core.find_path.find_path_core.base.GridPathFinder.
В этом планировщике предполагается, что каждая координата
состояния разбивается на равное число точек (_gridSize)
Получается, что в данном планировщике одно и тоже пространство конфигураций описывается двумя пространствами: вещественным пространством состояний и целочисленным пространством координат. При этом размерности пространств совпадают.
Путь ищется за счёт перемещения по сетке планирования. Когда путь на сетке найден, каждой его точке сопоставляется состояние робота, и на их основе строится путь.
После того как путь построен, необходимо добавить исходные точки планирования (начальную и конечную) по краям пути.
В таком планировщике добавляются две новые ошибки: не удалось определить стартовую точку на сетке планирования или конечную:
/**
* Ошибка планирования: не удалось найти стартовую точку на
* сетке планирования
*/
static const int ERROR_CAN_NOT_FIND_FREE_START_POINT = 2;
/**
* Ошибка планирования: не удалось найти конечную точку на
* сетке планирования
*/
static const int ERROR_CAN_NOT_FIND_FREE_END_POINT = 3;
В начале планирования состояния переводятся в соответствующие координаты на сетке планирования. Если состояние, соответствующее сетке планирования приводит к коллизии, то ищется соседняя свободная от коллизий точка на сетке планирования.
/**
* @brief поиск координат соседней свободной точки
* Это - рекуррентный метод, он пробует прибавить -1, 0 и 1
* к каждой из координат из интервала [pos, maxPos] включительно
* @param coords координаты исходной точки
* @param pos начало интервала перебора
* @param maxPos конец интервала перебора
* @param state состояние
* @return пустой вектор, если точку не удалось найти, в противном случае - вектор
* координат
*/
std::vector<int> GridPathFinder::_findFreePoint(
std::vector<int> coords, unsigned long pos, unsigned long maxPos, const std::vector<double> &state
) {
if (pos > maxPos) return {};
// рекуррентно для каждой координаты перебираем три варианта: вычесть из неё 1,
// прибавить 1 или ничего не делать; для каждого варианта запускается новый такт рекурсии
// по следующей координате
std::vector<int> tmpCoords = coords;
for (int i = -1; i <= 1; i++) {
tmpCoords.at(pos) = coords.at(pos) + i;
if (checkCoords(tmpCoords))
return tmpCoords;
else {
if (pos < coords.size() - 1) {
auto newCoords = _findFreePoint(tmpCoords, pos + 1, maxPos, state);
if (!newCoords.empty())
return newCoords;
}
}
}
return {};
}
Если среди соседних точек не нашлось свободной от коллизий, то задаётся соответствующий код ошибки и возвращается пустой путь.
Также добавлена возможность строить маршрут по сетке планирования, задавая сразу координаты на ней. При этом всё равно возвращается путь в операционном пространстве:
/**
* поиск пути из состояния `startCoords` в состояние `endCoords`,
*
* @param startCoords начальные координаты
* @param endCoords конечные координаты
* @param errorCode в эту переменную записывается код ошибки
* @return путь по сетке планирования
*/
std::vector<std::vector<double>>
findGridPath(std::vector<int> &startCoords, std::vector<int> &endCoords, int &errorCode);
Ноды планирования
Часть планировщиков работает с использованием нод.
Нода планирования описывается структурой
project.core.find_path.find_path_core.base.PathNode.
Сам класс планировщика -
project.core.find_path.find_path_core.base.NodeGridPathFinder.
Нодами называются записи об обработанных точках на сетке планирования и некоторая вспомогательная информация. В данном фреймворке у нод хранится метрика расстояния от стартовой точки до рассматриваемой.
/**
* метрика расстояния от стартовой точки до рассматриваемой
*/
double sum;
Можно вычислять расстояния между углами поворота звеньев,
а также расстояния между положениями звеньев. За эти компоненты отвечают
коэффициенты _kG(1) и _kD(0) соответственно. В скобках указаны
значения по умолчанию.
Чтобы не использовать ту или иную компоненту, сделайте соответствующий
коэффициент нулевым.
Также хранится порядок ноды
/**
* сколько нод отделяют рассматриваемую от стартовой
*/
unsigned int order;
Чтобы восстановить путь, у каждой ноды указывается предок
/**
* Указатель на ноду предка
*/
std::shared_ptr<PathNode> parent;
Суть алгоритма планирования с использованием нод сводится к взятию самой удачной ноды из списка на обработку, обработке её и добавлению в список всех её ещё не рассмотренных соседей. Этот список называется открытым множеством.
Чтобы сделать его упорядоченным, необходимо использовать структуру-указатель на ноду с возможностью сравнивания метрик:
/**
* Указатель на ноду с возможностью сравнивания
*/
struct PathNodePtr {
explicit PathNodePtr(std::shared_ptr<PathNode> ptr) : ptr(std::move(ptr)) {}
std::shared_ptr<PathNode> ptr;
bool operator<(const PathNodePtr &obj) const {
return (this->ptr->sum < obj.ptr->sum);
}
};
Множества хранения
В самом планировщике открытое множество хранится в поле _openSet:
/**
* Открытое множество нод для обработки (упорядочено по метрике)
*/
std::set<PathNodePtr> _openSet;
Чтобы хранить все обработанные точки в закрытом множестве, используется множество на хэшах, при этом в качестве исходного значения хранится свёртка координат
/**
* свернуть координаты coords в скаляр (size - размер СК)
* @param coords координаты
* @param size размер вдоль каждой оси
* @return свёртка
*/
unsigned long bmpf::convState(std::vector<int> &coords, int size) {
unsigned long code = 0;
int m = 1;
for (int coord: coords) {
code += m * coord;
m *= size;
}
return code;
}
Такой алгоритм гарантирует биективное (один к одному) отображение множества координат и множества свёрток, поэтому вместо высчитывания хэша от объекта ноды, высчитывается хэш от свёртки
/**
* поиск координат в списке закрытых нод
* @param coords координаты
* @return флаг, содержатся ли координаты в закрытом списке
*/
bool NodeGridPathFinder::_findCoordsInClosedList(std::vector<int> &coords) {
long code = (long) convState(coords, _gridSize);
return _closedStateConvCodeSet.find(code) != _closedStateConvCodeSet.end();
}
Перебор нод
Все простые планировщики наследуются от NodeGridPathFinder. В каждом из
них реализуется метод
/**
* для всех соседей текущей ноды метод должен добавить только
* подходящих в множество _openSet, если один из соседей
* имеет целевые указания, то возвращаем указатель на эту ноду,
* в противном случае должен быть возвращён nullptr
* @param currentNode
* @param endCoords
* @return
*/
virtual std::shared_ptr<PathNode> _forEachNeighbor(
std::shared_ptr<PathNode> currentNode, std::vector<int> &endCoords
) = 0;
Иными словами, для реализации планировщика на основе NodeGridPathFinder,
требуется описать, как именно на основе текущей ноды следует перебирать всех
её соседей.
Такой алгоритм перебора принято называть
Более подробно об алгоритмах планирования подобного рода можно прочитать здесь.